

Confluence Blog Posts
Confluence blogs are a great way to capture point-in-time information and share it with your team.
Confluence comes with two basic resources, pages and blog… Pages always made sense to me - they’re the stuff I put into Confluence for other people to use (there’s a biiiiit more to them then that, but I’ll cover that later). Blogs, on the other hand, remained a mystery for a while.
Personally I’ve always thought of blogs as something an individual or company will post online to share their thoughts on something. On the individual level the phrase “check out my blog” can be a bit cringe-worthy… and on the company level they can be a bit bland. This understanding may have caused me to ignore the Confluence Blog for longer than necessary, but I eventually figured out that they both exist, and are useful.
Where they are
Blogs exist in spaces (much like pages), however, instead of appearing in the “Content” section, they appear in the Sidebar.

This makes the visually one of the first things people will see when they browse the page (and something I glossed over for years..). Note that your Space Admin can turn off blogs, so you may not even see this option! If it’s missing, contact your Space Admin to see if they’ll turn it back on.
How they’re similar to Pages
Pages and Blogs share a number of similarities:
They exist in a space - Pages and Blogs exist in one, and only one, Space. This means they are generally controlled by Space access, allowing admins the ability to easily limit visibility by not providing access to the space.
They can be Restricted - Both resources can be restricted on the individual level, allowing authors the ability to hide, or control editing, one their content.
Robust editing - Both resources share the same editing capabilities (Headers, formatting, sections, etc).
Macros - Both support Macros, allowing you to easily extend functionality and interact with other resources.
How they’re different from Pages
While they do share many similarities, there are some major differences between the two resources that are important to understand.
Templates - Blogs do not support templates. This means you’ll be starting from scratch every time. Personally I get around this by using a (very) simple format for my regular blog posts (sometimes I Just copy/paste older ones).
Hierarchy - Blogs do not show up in a hierarchy (e.g. a blog cannot have a parent or children).
Visibility - Unlike pages, Blogs can be disabled in a particular space by a Space Admin. This lets admins clear up space in the sidebar if they’re not used, but can make it a bit frustrating if folks are looking for blogs, but can’t find them.
Display - Blogs are displayed chronologically, allowing folks to browse by year or month. This differs from Pages, which are displayed in their hierarchy.

What I use them for
I started using blogs to capture “point in time” updates or information and left things that update over time, or are frequently looked at, to pages (e.g. “meet the team”, policies, etc). Over time this has included things like:
Weekly Updates - Details of what a team has accomplished over a week are a great thing to put in a blog… after all, it’s not like that will change over time, and having them in the chronological format makes it easy to browse through and see changes.
Product Releases - Another item that is a great “snapshot” of what’s happened, and easy to display chronologically.
Their chronological listing can also make Blogs a great way to capture performance information, or your accomplishments over time. This makes it easy to search for them since you can filter your search just to Blogs and anything with “achievement” in the title or label.
Other thoughts
Like any tool it’s important to consider WHY you’re using it before you just jump in. Personally, I’ve found Blogs to be useful to help chronicle activities over time, but groups may find other uses for them. Some groups may also opt to hide them entirely, and just focus on pages. Neither approach is better than the other, but in some cases one may make more sense for your team.

Challenges faced when updating Confluence
There's many challenges to face when deciding to improve your organizations Confluence
Confluence is. a great tool, but, like anything, over time it will wear down. Pages will get stale, content won’t be updated, and some information that should be there is just missing. Ideally organizations counter this by performing regular reviews of important or high-priority information in Confluence every 6-12 months. This helps ensure the tool remains useful and doesn’t get too cluttered.
Much more commonly, however, groups neglect to update Confluence, resulting in spaces and pages that are less than useful. Eventually someone will decide they need to do something about it - and run into challenges and opposition.
Below are several challenges I’ve come across (but are by no means ALL the challenges out there!), as well as some ways to get around them.
Challenge #1 - What is Confluence?
Someone not knowing what Confluence is, or realizing they have access to it, is more common than you think. On the one hand this is a bit crazy since organizations pay good money to utilize it, but on the other hand it’s entirely understandable as many times knowledge management isn’t at the forefront of anyone’s mind.
Overcoming this challenge can be hard as you’re working with someone who has zero understanding of the usefulness of Confluence. Here, focus on some of the following to help overcome it:
Education - Start with the basics. What challenges can Confluence help your organization solve? How is it already being used? What efficiencies are gained from it?
Demonstrate - I find it handy to have a demonstration space setup in advance so I can walk them through what a good setup looks like. This lets them get hands on to see what it’s like.
Challenge #2 - Where to begin?
Many times I find it challenging to pick a single point to begin - after all there can be dozens or hundreds of spaces in an instance, so choosing one to start improving can be hard.Even within a space it can be challenging to pick a single area to improve.
Taking an educated guess is a great way to overcome this challenge. Ask yourself the following questions to help target an area to start with:
Are there specific areas where most workers are required to go or would find information? Something like a company hub / employee central that houses general information can be an easy target.
Are there any areas that have low traffic? Low-traffic areas can be a good target for improvement, but you’ll have to determine if they’re worth it.
Is anyone screaming about it? You may be getting complaints that XYZ area isn’t up to speed - this makes this step easy, just go there and look a round!
Challenge #3 - "We don't have the resources"
Organizations have a lot of priorities, and I’ve never met one that put improving Confluence up near that top… this makes this objection incredibly common when you’ve identified some work that could be done. Typically I’ve found that more budget isn’t needed, making this a matter of getting some person-hours to help out. Typically I can tackle it myself, but sometimes getting another expert in is needed.
Here’s a few ways you can approach this one:
Determine the minimal amount of work needed - Take your plan and boil it down to just the necessary changes or updates. Challenge yourself to make Confluence more useful while minimizing your ask. This is a good exercise in general, but will help you focus on the important parts.
Realistically estimate the work - Take some time to understand exactly how much time or money it will take to do what you’re planning. This won’t necessarily overcome this objection, but it will demonstrate you’ve done your homework, and set you up for the next item. This will also help you figure out what other folks you need to help you, and how much of their time you need.
Can you do it on your own - Many times I’ve found the updates I see are things I can do in my “spare” time at work. Sure, it will take longer since it’s just me dedicating a few hours here and there, but by taking on the core load yourself, you help deflate this objection.
Challenge #4 - Not a priority / “This isn’t important”
Another very common objection is that it’s not a priority for your organization. I completely understand this, as there’s a lot going on… however, as you’re likely aware, having a Confluence space that isn’t organized is almost worse than not having one at all.
For me, this challenge is best overcome by using numbers and gathering feedback. These both give you things to point at when making your case, helping show that it should be a priority.
Metrics - Pull whatever numbers you can on how much Confluence is utilized. How many times are pages with critical information accessed? How frequently are they updated? Are they even being used at all?
Feedback - Solicit, compile and analyze feedback from other people in your org about Confluence. What frustrates them? How much time do they waste struggling to find information?
Challenge #5 - "It’s always been this way / It's not broken"
Organizational inertia can be very hard to overcome… folks get used to things being a certain way and become incredibly resistant to changing anything about it. That, however, doesn’t mean that we can’t do better. Fortunately the way to overcome this is the same as Challenge #4 - gather information about the pain that is currently being experienced and quantify it.
Challenge #6 - "XYZ software does that"
Organizations have many, many tools (one place I worked had over 200!). This makes it highly likely there is another, similar tool, that does (at least part of) what Confluence does. Unfortunately this will result in folks pointing to the other software and saying “we don’t need to improve Confluence”.
My approach with this objection is education. Take time to clearly lay out the intended use of Confluence as the source of truth for information (or at least an index pointing the way). Reinforce that while information doesn’t have to live in Confluence, people should be using it as a first point of contact while looking for information.
Gathering feedback is also a good approach - especially if people are confused about where to go to get information or which system to use.
Challenge #7 - Resistance to archiving/deleting / No alignment on how to manage old content
This one pops up once you get your project started and have identified content that has to be retired. Content that has outlived its usefulness should be either archived or deleted as it just clutters things up for everyone else.
This pushback could be the result of a few things, so your approach will differ:
If they’re unfamiliar with Confluence - They may just not know you can safely archive items and still find them. If this is the case, educate them on how the feature works. Give them a live demonstration of how easy it is to archive, view, and recover, that information to help them understand how easy it is.
They think it’s still useful - Sometimes they’ll think that the information is still needed. This is where your metrics and feedback come in handy. In many cases you can show them that it hasn’t been viewed or updated in a period of time, or that only a small number of people use it. Getting hard data - or anecdotal data - can help them see that the content should be retired.
Challenge #8 - Resistance to using the tool
This is a very common challenge with Confluence in general. Many times people don’t want to use it at all, or only in a limited way. Overcoming this can be particularly challenging, especially if they’ve already made up their mind about it
Depending on how severe, this can take time to overcome, and is mainly education-focused. Take time to understand why they don’t want to use the tool, then tailor your response accordingly.
Challenge #9 - Disagreement on design principles
For me this is a less-common objection, but one that still does come up. Sometimes a group will have a particular idea of how things should be set up or look, which can clash with another group’s ideas. Taking time to understand each group’s desire is important here, as you’ll want to b e sure you understand their disagreement.
From there, you may need to educate them on what is possible (e.g. you may not be able to do XYZ idea given constraints), or mediate a compromise with another path.

Confluence Databases for Project Tracking
Databases offer a number of features that help project managers stay on top of tasks in Confluence
Keeping track of all the pieces of a project can be challenging. Fortunately, there are a ton of different tools out there to get the job done. Recently, however, I’ve been using Confluence Databases to see how this feature can help me track project work, and I’ve found it to be pretty good at handling small to mid sized projects.
What is it?
Confluence Databases sit somewhere between a table/spreadsheet and Jira. They live in the content tree of a Confluence space, and look similar to a table. That is where the similarity ends though, as they have a number of functions that are very useful in tracking project statuses. This includes things like tracking specific users, linking to Jira tickets or Confluence pages, and even linking to other tables.
Features that help project managers
There’s a few specific features that I’ve found make a database very useful to project managers.
Saving (and easily sharing) filter views is incredibly useful. This allows me to create a view once, then share it with specific groups. I could, for example, share a list of new tasks with analysts so they can build out specs, or a list of blocked items to bring up at the start of our calls. Since the filter is saved in the URL this is as easy as copying/pasting, and can be bookmarked.
The native integration with Jira is another great feature as it’s highly likely I’ll be using Jira if I’m in Confluence. Being able to link a line in my database with 1 (or more) Jira tickets lets me keep my developers in Jira while still giving me easy access to what’s going on in there. This allows me to easily give my stakeholders a view of the project that isn’t too “technical” while preserving direct links to more information in case they want it.
Finally, configurations can be copied into a new database. This lets me easily make a clean copy of the database for a new project and preserve all of the columns and other settings I have. This means that once I have a good structure in place I can make as many copies as I need to, slot them into the proper place of Confluence, and not have to worry about deleting anything.
Database Setup

I’ve been using Databases to track relatively simple projects, so I added in a number of basic fields:
Task Name - A text field containing the name of the task
Status - A Tag field indicating the status (To Do, Blocked, etc) of the task
Owner - A User field with the task owner
Due Date - A Date field with when the task is due
Jira Ticket - If the task has a jira ticket it’s linked here
Jira Ticket Details - The assignee of the linked Jira ticket
Documentation - A link to any Confluence pages with more information
Why not just use Jira ?
There is an interesting question of why wouldn’t I just have used Jira to track my project work. There’s a few reasons:
Trying something new - I find it’s really important to expose myself to new ideas, tools and methodologies. Not only will this give me more options for managing projects, but I might find something useful that can be applied elsewhere.
Light weight - Setting up a Jira project takes time and sometimes requires a Jira admin to help with setup and changes. Both of these things may be in short supply, so having an option that is more robust than a spreadsheet (which may be flexible, but lacking features), but less heavy than a full-on Jira project is very attractive.
Presentable - I’ve found that many stakeholders don’t like going into Jira to get information on how things are going. Having another option, like an easily-accessible page in Confluence, has been great as people actually use them.
Flexible - The ability to easily add new columns, save filter-views and share information quickly makes databases very attractive. It hardly takes any time to add or adjust data, making it easy for my team to keep things up to date.
Integrations - Being able to instantly connect Confluence pages and Jira tickets makes Database more data-rich. For example teams can easily see any related Jira tickets, and stakeholders can easily access documents from one spot.
Why not just use a spreadsheet?
Spreadsheets are a great tool for many things, and they’re incredibly flexible. This makes them the go-to for many project trackers, especially if they don’t need specific features or integrations. That said, use a Database has a number of advantages:
Everything in one spot - If you’re already using Confluence you’re likely storing other project documentation in there as well. Having a database to track your progress puts everything in one spot, in the same system. This reduces the administrative overhead needed to track, maintain and manage things, and also leads to
Integrations - Aside from the built-in integrations with Jira, having your plan in Confluence makes it a lot easier to reference on other pages, integrate with other information and make more easily available.
Presentable - Similar to #3 above, I’ve found a database is easier to share with others, and easier for them to interpret. While a spreadsheet may have all the info in there, it’s easy for someone to go to the wrong tab, workbook, etc. and get frustrated.
Re-use - The configuration of a database can be copied into a new database in a few clicks. This makes it incredibly easy to spin up new projects with the same setup as an old one. A spreadsheet would require copying, then deleting everything to start over.
Final Thoughts
Databases are a great mid-weight way to track projects. The biggest hurdle for me was just figuring out what fields to include and after that I found them easy to update and use. Will they entirely replace spreadsheets? No, however, they do give project managers another great option to keep things on track.

New Confluence Beta Feature - Company Hub
The Company Hub makes it easy for people to find content in Confluence via a universally available link in the nav bar
Company Hub
Company Hub is a new beta feature for Confluence Premium and Enterprise that I think many folks will find very interesting. Up until this feature released we were stuck making a “central space” and hoping folks could find it.. but now there’s a highly visible, accessible page everyone can see to help direct them to content - the Company Hub.

What is it?
The Company Hub attempts to answer the question “What is one place everyone knows to go to for information”. It does this by making itself available in the navigation bar of every page, meaning it’s always visible. Prior to this feature the best way to solve for this challenge was to build out a space and call it something like “Employee Home” - but then you end up with folks not knowing where to look for it, losing it in a list of spaces, etc.

Features
The first thing I noticed in the Hub was the inclusion of two new macros (also available in Beta for Premium/Enterprise groups outside of the hub). Both appear to be aimed at helping folks more easily display information in a more visually pleasing way. Prior to having these I’ve been forced to use add-ons like Aura to make things look better.
The new macros are:
Cards

The Cards macro allows you to organize and display information visually. Each card can include information like a name and a link making it easier for folks to find content. I can think of a lot of good uses for this, from directing people to interesting pages, to lining up a process by step, to guiding new hires around the company.

Setting up cards
Setting up cards is simple - just add the macro, then adjust the general settings (applied to all the cards in the macro).
If a card is linked, you can have it also show the last time the linked page was updated, and the image for it’s owner (helpful so folks know who to go to or to judge stale-ness)

Settings per card
Each individual card also has information associated with it, including a link to other information, description title, and - interestingly - an integration with Unsplash so you can find images to add.

Cards of different sizes
You can also arrange cards in smaller sizes or vertically for more display options
Carousels
Similar to cards, these display a rotating series of up to three items and help you showcase information.
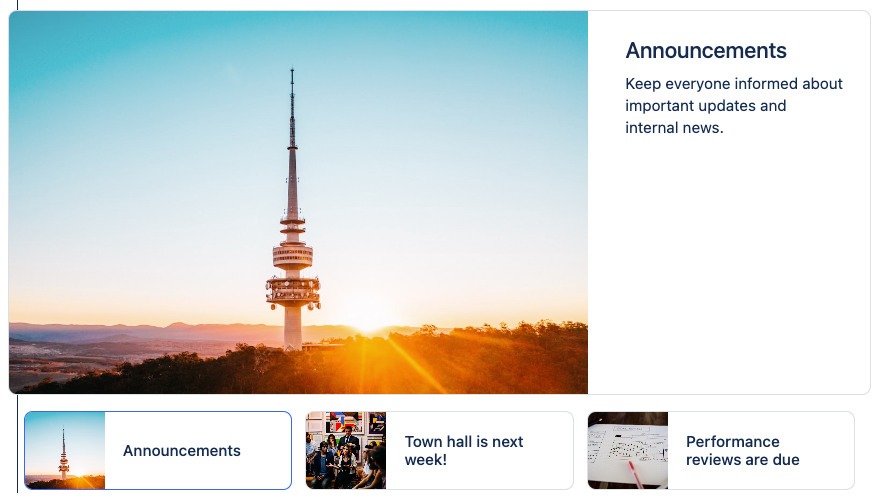
These support up to three cards that users can click on for more information, or to link out to other resources. Each one supports a link, title, description and the same Unsplash integration as the Cards macro.

I can think of a number of uses for Carousels, ranging from highlighting regular information, to calling out specific parts of a how-to or process, or just breaking up the page with something that looks prettier.
Other Hub Features
While the Carousel and Card macros can be used on any piece of content in Confluence, there are a few Hub-specific features.
Naming
The default name of the hub is “Company Hub”…. which is boring. So, you can also name the Hub anything you want. This name appears on the Hub itself, but also in the navigation bar. I can easily see groups choosing something like “Home Base”, “Click here for info” or basically anything else to attract attention.

Permissions
The Hub also has its own permissions. These function almost identically to space permissions so you’ll have plenty of flexibility in determining who can view and edit the page.
One thing to note is that permissions are found under the “more actions” menu. Personally I find this a bit annoying as they’re a bit hidden, but they do function similar to Space permissions so you get a lot of control over who can do what.

Use Cases
Given the universal visibility of the Hub link in the Nav bar the Hub is an excellent place to put company-wide resources. Personally I can easily see HR/People teams leverage this to build a clearing house of information for workers - not only including pointers to HR policies, benefits, etc. but also things like
Calling out new hires - Use a carousel or card to link out to new folks
Company marketing materials - Link to the company blog, or references for workers (templates, brand materials etc)
Index team spaces - Provide easy access to each team’s spaces in Confluence
Company events - Hype up upcoming company events or provide access to the company calendar
Basically any company-wide information should be posted or linked from here. I wouldn’t use the Hub itself to host a lot of information, but instead leverage it for pointing folks to the appropriate spots. I also don’t think the hub should be a very long page - people should be able to use it to quickly find what they need and get to it - not scroll endlessly.
Potential Challenges / Limitations
Maintenance
Ensuring the Hub is regularly updated and maintained is another easy challenge I see cropping up (this is by no means unique to the hub!). If workers are told it’s the clearing house for information and find it to be out of date, incorrect or missing things, they’ll stop using it. That type of trust is very hard to rebuild, so groups using this feature should ensure they have someone regularly maintaining it.
Visible to Free / Standard
Less of a challenge and more of an annoyance is that the Hub is visible even for Free and Standard subscriptions… despite being unable to use it! There’s no way for admins to turn the link off, so those groups are essentially left with a sales-banner staring at them all day. (I certainly understand the need to upsell/etc. But having a way to disable the link would be nice).
It’s Beta
The hub is currently a beta release, meaning it can (and will!) change rapidly.There’s also a (very small) chance Atlassian decides that the hub shouldn’t be launched, meaning it would disappear.
Final thoughts
Overall I”m excited to see how more groups leverage the Hub. I think it’s a great feature that can help shorten the distance folks have to travel to find useful information. Certainly something worth checking out if you’re on Premium or Enterprise!

Mission Control for Confluence Spaces
Mission control is a central place to get metrics and info about your space
One of the things that makes missions to space so successful is mission control - a room full of really smart people who help the astronauts solve complex challenges in real-time. While Confluence isn’t as complex as sending people into space, it still has levels of complexity that require us to manage it (and sometimes get our own room of smart people to help solve challenges).
Recently Atlassian released a feature called Mission Control that helps do exactly that. It lives in space settings and is full of resources to help admins manage their space.
Read on to learn more - and check out this youtube video detailing the feature.
Start at the top

At the top you’re presented with three metrics - the total amount of content in the space, the number of content views, and the amount of content created, plus a change over the last week for all of those. I find these three numbers are useful to determine how well the space is being utilized. For example, if the amount of content in the space spikes, it suggests something is going on in the related area. If the number of views falls off a cliff, I would want to dig into what happened.

Access questions
Next we get a view of access to the space in the form of external access and admins. I really appreciate having external access immediately available as I am (more than) a bit paranoid about external access. Seeing who the space admins are is also useful in the event I need some backup, or need to audit.

Metrics, Metrics and more Metrics
While the top focuses on high-level information about the general setup of the space, the middle gets into the numbers. For me this section helps me identify how the space is doing, and helps highlight areas I should look into. All this information can be displayed daily/weekly/monthly over the last 7/30/60 days via a selection at the top.
Metrics include:
Content views - The total number of views in the time frame, split by content type (pages, blogs, whiteboards).
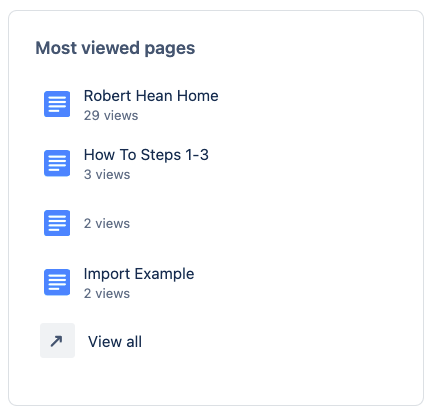
Move viewed pages - The top 3 pages by visits. This is a great way to find your most popular content. Also includes a link to view ALL you content by number of views.
Content created - The total number of content created in the time frame. I find this more useful in spaces where I’m not the sole creator, or spaces with a broad audience. I use it to gauge how interested folks are in contributing to the space. A spike could suggest a new initiative or project, and a dip could suggest a project is winding down.
Content updated - I really like this metric as it helps me figure out how “fresh” the space is. Over time we can expect some pages not to be updated, but if we see a constant amount of updates being made it suggests that the space is live and being actively used.
Total content - The total amount of content to the space by type. Useful for seeing how a page is growing, and what types of content your team uses.




Managing content
Below metrics we get two more valuable pieces of information. Prior to Mission Control this information was available, but could be hard to get to. Having it all in one spot makes it MUCH easier to dig into and manage.
Inactive pages - Any page that hasn’t been updated or visited in 6 or more months. This is an incredibly useful thing to track as you should be either updating or archiving that type of content (e.g. stuff that’s not being used). Getting a list that’s easily accessible makes this process a LOT easier..
Pages without active owners - As folks leave your organization (or lose Confluence access) any page they’re an owner on will no longer have an active owner. This is an issue as the owner is the point of contact for the page and should be actively maintaining it. Getting a list of pages with inactive owners makes it much easier to go find new ones and ensure your content is maintained.


Security
The final section of mission control displays the total number of active public links, and the number of views those links are attracting. I find this to be very useful information - but only if you have public links turned on.Personally I’m a bit paranoid about publicly facing information, so having these metrics easily accessible helps put my mind a bit more at ease.
Active public links - The total number of active public links in the space (including a link to see them). Spikes in this metric could suggest someone is sharing information they shouldn’t, or that a new initiative is going live that requires public links. Either one should be investigated to valid it’s an appropriate use of the feature.
Public link views - The number of views made against public links. Similar to the active links, a spike could just mean something went live (e.g. a new feature or guide), or could suggest your links are being abused in some way. Definitely worth checking out if you see spikes in the metric.

Final thoughts
Mission control is a great step in the right direction for helping manage spaces, particularly ones that are accessed by larger groups (e.g. employee hubs) or are for sensitive things (e.g. special projects). Having access to all this information in one space is a very useful tool and one I hope to see more of in the future.

Using Confluence databases for a FAQ
Databases are a great tool for organizing data… including FAQ.
I frequently find myself using Confluence to track Frequently Asked Questions (FAQ). I’ve done this for HR/People teams, Customer Support, Engineering, and many others, and it’s a great use of the platform.
Historically I’ve accomplished this one of two ways:
Parent with Children - Have a parent page called “HR FAQ” and then have a single child for each question and answer. (Check out that approach here)
Headers and sub headers - Have a single page with all the FAQ and use headers (and the Table of Contents macro) to break out questions.
Since the launch of databases, however, I’ve found myself wondering (and have been asked about) how databases could support an FAQ.
What are databases?
Databases are a relatively new feature to Confluence that allow you to build a structured data set into Confluence. On the surface they can look a bit like a table but they go far beyond the humble table and start to overlap (a bit) with the concept of a Jira ticket.
Each column of the table is a piece of data about something. In our FAQ this would be information about the question - its name, an answer (or link to one), the owner, category and more.
Each row is an entry - in our case, a question.

Databases also include some additional features that make them very useful:
Saving filtered views
These are a saved list of all rows that meet some criteria. For our FAQ this could be all IT related questions, or anything unanswered.

Different visualizations
Databases display info in a tabular view by default, but there are other options include cards and a board view. For me the table view works best for a FAQ, but teams may prefer the others as well.

Search
Databases have their own search bar. This allows users to easily search within just that database. This makes it easy for your users to find answers in your FAQ.

Catch up on other basic features in this video:
How do they help build an FAQ?
Databases live in the content tree, making them very simple to insert where people will look for information. They also allow multiple entries, keeping their presence in the content tree limited (if you go with the “one page per question” route you end up with a lot of pages, which can easily turn some teams or groups off from considering it as an option).

Since databases allow for multiple columns you can also include a lot of information about questions. Things like who asked it, what type of question it is, what version it controls, etc. can all be included (This could also replace using page properties if you’re using that to track this type of information). This allows you to build very robust answers, including linking out to reference content and more. You can even pull in excerpts from linked pages, potentially allowing you to include an answer directly in the database automatically.

Anyone with edit access can also add new entries to the database, making it very easy for someone to be able to add questions. Imagine if anyone at your organization could drop in and add a new question which you can easily filter for and assigning to someone to answer.
What are the downsides of using a database for a Confluence FAQ?
There are a few downsides to using a database to host questions and answers:
Jira Knowledge Base - JSM appears to only see Pages as answers to questions. This means if you’ve got a JSM instance linked to Confluence answers in your databases can’t currently be displayed… so if you want to use this to support your help desk you’re a bit out of luck (although you could use this to support agents, or others who leverage Confluence, but they’d have to access it independently of JSM).
Control - Like other forms of content you can place restrictions on the database… However, those restrictions apply to all records. This means you can’t “lock” a single row and prevent anyone but yourself from editing it. This opens up the risk that answers will be changed or added when they shouldn’t be. You can solve this by restricting editing to only a few folks, but then you face a bottle neck around adding new questions.
Confluence search - Individual database entries currently are invisible to general Confluence search. This means someone searching from another piece of content may not be able to find your FAQ.
Final Thoughts
While using a database to host FAQ is a great way to store info it does present it’s limitations. This makes them less-than ideal for some applications, however, for instances where you have an internal team who knows which database to look at these are incredibly powerful. Similarly if you are able to share saved views with internal users you’ll likely get a lot of utility out of them.
More Info
See how to set them up in this hands-on video:

Improve your short updates
Sending updates is really easy… but unless you include this simple thing they can cause a lot of headaches!
A large part of my life is spent creating, and sending, updates. Updates on how projects are going. Updates on a bug a customer is experiencing. Updates on how the updates are going… it goes on.
This means I spend a lot of time thinking about how those updates are read, and how they can be more effective. Take this update, for example:
"Rob is working on the Task"
This isn’t a (very) bad update. It does share some important information - namely that Rob is working on the Task. This, by itself, is important to share - after all, many times folks are mostly nervous because they don’t know if someone is working on the Task. When I see someone post an update like this I breathe a sigh of relief as it means they’re at least paying enough attention to provide the basic information about what’s going on.
What’s wrong with that?
Updates like this one, however, drive me nuts. While they do provide a bare-minimum about what’s going on, they also breed anxiety and frustration. They do this because they’re lacking a critical piece of information - when will you share more information?
They don’t answer “When will the Task get done” or “when will I get an update”. This information is arguably more important than “Rob is working on something” as it lets everyone know when they’ll get more information. Updates missing those two pieces of information are dangerous since folks will wonder “When will I get what I need?”.
What’s the fix?
Fortunately the fix is fairly easy… just add a time and date for a follow up. For example, consider:
“Rob is working on the Task - I’ll provide an update tomorrow at noon”.
That extra bit at the end immediately answers the question “When will I get more information”. Note that it doesn’t even require you to add anything about what to expect - just that you’ll post something. At the very least it will stop someone from immediately asking “when will it get done”, but it does far more - it gives the reader peace of mind. They don’t have to worry too much about what’s going on because they know they’ll get something tomorrow at noon.
Of course, this requires you to actually send an update tomorrow at noon! That update, however, doesn’t have to be “and the Task is done” - it could just be a followup letting folks know it’s still outstanding. This does run the risk of a string of “I’ll update you tomorrow” updates, but ideally each one includes a bit more information on where the task is (e.g. what’s the blocker, what other info is there).
The best part of this is that it takes basically zero effort - just add a short bit of text to your updates on when you’ll give more info and you’ll save everyone a lot of frustration!

When to use Confluence or Jira
Confluence and Jira are complimentary, but different!
Almost every company I’ve worked at has provided access to both Confluence and Jira. These two tools offer a ton of functionality and features that can help make our lives easier, but many times I find myself asking myself “which one should I use?”.
On the surface this should be an easy question - after all Confluence is a knowledge base and Jira is for ticketing. This distinction, however, can easily break down - Confluence supports task tracking and can be used to manage work, and Jira can easily be used to house information about things in the form of task descriptions, fields and more.
So let’s take a deeper look at these two systems, their differences, and why we may choose one of the other in some cases.
Confluence
Confluence is intended to serve as a collaborative platform for sharing, maintaining and creating information. It excels at allowing individuals to work on content together, manage and store that information and easily add more as it is created or discovered. Personally I find myself using it mainly to keep track of what I’ve been up to in the form of meeting notes, product updates and other notes.
Part of collaborating, however, includes tracking tasks or action items. For example, during a meeting I may record that Bob will update the server on Friday, or that Sally will connect with Procurement about an important contract. To support this, Confluence allows us to track tasks, which can have assignees, descriptions and due dates… which sound awfully similar to a Jira ticket.
Jira
Jira is intended to help teams manage work in the form of tickets. Tickets can have different types, for example bug, task, story, etc. Each type of ticket can also follow its own workflow, so tasks can have a different set of steps necessary for completion than bugs. Additionally tickets can have any number of data fields attached to them allowing teams to collect and track many kinds of metrics relative to their work.
Part of managing work, however, includes collecting information about what you’re doing. For example an HR team may build out policies using Jira tickets and include information about them in the description field. An engineering team may collect API documentation on a ticket as well… both of which sound awfully similar to a Confluence page.
How to choose
Given the number of similarities the systems share (tracking an item of work, collecting information, etc) it can sometimes be hard to know which one to use. For example, I could keep Jira open during meetings and add new tickets as action items are identified. I could also open up Confluence any time I learn something new about a task and add it to a page.
My general rule is to use whichever one requires the least amount of work. Typically this results in me using Confluence as it makes managing information easier, and also supports tasks. Only when I get to a point where Confluence tasks don’t support what I need (e.g. adding more information to a task, requiring a workflow or approval, etc) will I switch to Jira.
Fortunately both systems are tightly integrated, allowing Jira tickets to be posted directly on Confluence pages and Confluence pages to be easily linked to Jira tickets. This makes it very easy to span both systems when I need to.

Seeing your own improvement
"If you don't look at code you wrote a year ago and think is garbage you aren't getting better"
I heard that from a software engineer and have spent a lot of time thinking about it. At it's core it's reminding us that our skills grow over time, and having something we've done in the past serves as a great baseline to compare our growth to.
I recently reviewed my Knowledge Base Fundamentals course over at Udemy and immediately thought of that quote. To be honest it's incredibly humbling (and a bit painful) to look at older work and compare it to what I'm capable of doing now, if only because I see all the areas I'm now able to do better.
This particular course was created over 2 years ago. I had a fairly good grasp on concepts like editing, lighting, scripting and more... but now that level feels so... basic (and I'd bet I'll say something similar in a year about where I'm at now!).
After taking a look at the course I determined that I could make it a much better experience for students in a number of ways. I realized that my own skills had grown substantially and would allow me to produce a much better course. This was an incredible experience in realizing I've changed in many ways:
Ways I improved #1 - Scripting
Originally the course was entirely "talking head" and scripted entirely in advance. This required a lot of time and energy to create and edit the script, but it did result in me knowing exactly what I'd be saying. Unfortunately this approach also resulted in me getting a bit “stuck” at times as I felt trapped by the script. This led to several, frustrating, instances of having to delete a lot of work and restart as I couldn’t figure out how to work in the newer ideas I had.
My general approach has since changed to instead using slides with bullet points. These guide my discussion, allowing me to explore more areas or go "off script". It also frees me from writers block / having to rewrite a script. I also find forcing myself to distill something into 3-4 bullet points a good exercise in determining what is really important. This helps focus my ideas and helps improve the final product.
Way I improved #2 - Filming
Shooting the scripted content was a pain. Not only was lighting a mess (see the fun shadows in the image below), but I had to juggle a camera and a teleprompter. Making a mistake required me to reset almost everything and rewind so I could re-record that section. The audio setup (a shotgun mic on the camera) also required a lot of work in post to cleanup as it captured a lot of background. It didn’t sound bad… but it didn’t sound good either.
Now I film at my desk with a boom mic (much less background) and a dedicated lighting rig that handles most of the lighting issues. The change in lighting alone makes me much happier - no more random shadows on me, and since I switched to smart bulbs I have much better control over the color temperature (which makes editing a bit easier.
Way I improved #3 - Editing
Editing a talking head can be a pain. Any cut is almost immediately obvious, and I didn't know how to cover those up the first time I shot the course. (Now I know to either zoom in or out slightly, or use b-roll to cover it up...). I also made editing harder on myself when I was shooting by not giving enough time/space between words or sections. This resulted in some very tight cuts that sometimes distorted the message.
Now when I record I know to back up and restart an entire slide, or leave space between them. This makes it a lot easier to edit together and hide any mistakes. I also switched to using Davinci - a free editing tool (that is insanely complex and I only barely scratch the surface of). Davinci gives me a lot more flexibility in what I want to include (no more limits to the number of video tracks!), and has allowed me to create better content in post.
Way I improved #4 On-screen content
When I first filmed the course I was using iMovie (which is great... to a point!). I found it incredibly challenging to add on-screen content, and quickly ran into limitations. I frequently went into Canva to make a single on-screen element, download it, then upload into iMovie. This took a LOT of time (and frustration!). This resulted in a final product that lacked on-screen information. iMovie is also limited in what it can display in terms of text and other images. This made it hard to create something that fit my needs.
Now I just build out a slide deck for a lecture which has all the onscreen content I need and record from that. This greatly reduces the amount of post production work... and saves me a lot of frustration. I can create exactly the image I want, and when I record I don’t have to worry about what I’ll need to add in post.

ACA-920 Confluence Essentials Certification
The new Confluence certification is here!
I recently took (and passed) the newest Atlassian Confluence certification, ACA-920 Confluence Essentials. I’ve been using Confluence for almost a decade, but have never made time to take any formal training or certification on it, so when I heard a new one was available I decided to give it a shot.
Who it’s for
Unlike many certifications that are geared towards admins or super-users, this certification is geared towards anyone who uses Confluence. It covers topics around creating and editing content, navigating the system and general knowledge of how Confluence works (and what it’s for).
The certification is valid for 2 years, which seems fair given Confluence is constantly changing. You can also renew it by earning 50 continuing education credits.
How to prepare
Since Team ‘24 (Atlassian’s yearly conference) all training has been free (which I think is great!). They have an entire learning path that will prepare you for the ACA-920. Even if you’re not looking to sit the exam, this is a great resource to get a handle on everything you need to know about Confluence. The learning path is intended for someone who has zero background in Confluence, making it a great place for someone to begin their learning journey.
Other than the learning path the best way to prepare is to just use Confluence. If your organization has one jump in and start using it. If you don’t have access to one you can get a free one (instructions here). If you go the free route, however, you won’t have access to some of the features that will appear on the exam (notably no Atlassian Intelligence, and no Page Restrictions - both important topics!).
About 70% of the exam is focused around creating and maintaining pages, so be sure you spend time practicing creating content and working with others on maintaining it.
There is also an Atlassian-hosted session on the ACA-920 on July 17th where someone from Atlassian will go over the certification.
What’s on it?
The exam has 25 questions and you get 60 minutes to answer them all (more than 2 minutes per question!). I assume the questions rotate, but they are broken down into the following areas (full details here):
Intro to Confluence terms and navigation ~ 12%
Creating pages and basic editing ~ 35%
Advanced editing ~ 15%
Working with pages ~ 35%
Advanced features ~ 8%
Since 70% of the exam is taken up by creating, editing and working with pages make sure you spend a lot of time doing those tasks. Many of the questions related to it were easy to answer since it’s something I’ve been doing on an (almost) daily basis for years. Understanding the layout of toolbars and menu bars is another important area to learn (Honestly this was a bit more challenging for me since I tend to ignore a lot of the options).
The questions are all multiple choice, and fortunately many of the options could easily be ruled out as being the correct answer, so if you don’t immediately know the answer take time to exclude ones you know are wrong.
Tips on getting it done
If you’ve ever taken a certification before the same tips apply here:
Take time to read and understand the question - I sometimes miss questions because I don’t read the whole thing or really understand it… don’t be like me! You’ve got 60 minutes (over 2 minutes per question), so take time to make sure you understand it.. And if you don’t see tip #2
Don’t be afraid to flag a question and come back later - Reading it, then coming back later to read it again can help jog your memory. I do this A LOT when I’m not 100% certain of an answer.
Eliminate incorrect answers - If you can’t find the correct answer, begin to eliminate incorrect ones. At the very least this improves your odds if you have to guess, but many times most of the answers will be obviously wrong.
My thoughts
Atlassian claims that this certification is for anyone who uses Confluence, and they’re not wrong. It does require folks to understand the basics of using Confluence, which does impact anyone in an organization. Selfishly I’d love for more folks to understand these background concepts and ideas as it would make for a better system overall (and less headaches for me!). That said, I can’t really tell why someone would want to pursue it other than just wanting to earn it (like me).
Other Atlassian certifications, like their Professional series, are clearly targeted toward admins, a group that does need to prove their skills. This certification, however, isn’t one I can easily see an employer needing someone to have as a job requisite. We do see Confluence listed on job reqs, but using it is never a core part of a job.
So if you’re looking to add something else to your resume and are excited about it - go for it. Otherwise, you will get almost as much out of the free training and invest the $100 elsewhere.

Confluence Content Manager
The Content Manager is a great way to quickly archive, manage and arrange your content.
The Challenge
A big part of managing a confluence space (or any type of knowledge base) is keeping an eye on how fresh information is. Over time content builds up - which is great since you may need it in the future… unfortunately it’s also a challenge as much of that content may not be immediately useful as time goes on. Old versions of policies, information related to completed projects and even old product updates all fall into this category. They’re all very useful when they’re first created and shared, and then lose their usefulness as time goes on.
It can be challenging to figure out what content falls into that category. The best way I’ve discovered is to open up the page analytics for any given page and see when it was last viewed. This, however, doesn’t work on a bigger scale as you have to repeat it for every page you want to examine. Another method I’d used is to just look at my content every 6 months and archive anything older than a year old and then hope no one needed it. This is dangerous as I’m likely to archive something that folks actually use or need (not the end of the world, but annoying to fix and disruptive to work).
The Solution
A recent feature update called Content Manager (for premium and enterprise customers), however, is making managing content a lot easier. It provides a single place to go to to see everything in the space, including when it was last viewed and how many times it’s been accessed in the past year. This alone makes it valuable as you can see everything in a space all at once (instead of going through page by page). Even better, you can perform bulk archiving or deleting on as many pages as you like, giving you the ability to update entire sections of your space at the same time.
I’ve been having a lot of success using this on a regular basis (currently monthly) to see what content is actually being used, and then taking action to update, or archive, older things. This process used to take a very long time since I had to look at individual pages, so having something like the content manager is a huge time saver.
Where to find it

The content manager is available to premium and enterprise customers and shows up both under space settings and in the sidebar.
What can you do with it

The content manager shows you your space’s structure, including all parent/child relationships. Any content, including whiteboards and databases appear in it, giving you a complete picture of what’s in the space.
You can select multiple pieces of content by checking the box next to them, or use the more actions menu to action on a specific piece of content. Selecting a parent will select all of it’s children making it very easy to act on entire branches at a time.
Most importantly it shows you when it was last updated, last viewed and total views over a year. This makes it incredibly easy to identify content that is stale, and either a good candidate for being updated.
There are also two filters currently available to speed you up even more:
Inactive pages - any page that hasn’t been visited, commented on or updated (you can select the time period). This makes it incredibly easy to find stale content and take action.
Pages without active owners - Any page where the page owner’s account is inactive (e.g. left the organization). Since the page owner is typically who folks go to asking for updates or with questions, being able to easily get a list of all the pages missing active owners is a great tool.

Confluence Headers
Headers are a simple, easy way to make pages waaaay more useful.
Creating good content for a knowledge base or similar system is challenging. You have to determine what your audience needs, find experts who know those topics and ensure content is regularly maintained. There is, however, a very simple thing that can be done to improve almost every page in Confluence (and in many other similar systems) - use headers.
Headers are essentially just bigger text on a page, but despite their seemingly simple design they serve a number of important functions in Confluence.
Visually breaking up space

Before you keep reading, scroll to the bottom of this post, I’ve copied all the content, but left out the headers…. It’s a bit hard to read, no?
The first, and arguable most important feature, or a header is to visually break up space on a page. I’ve lost track of the number of times I find really good content, but find it hard to read because it’s all just one gigantic wall of text. Paragraphs can (and do!) help with this, however, when all the text is the same size it makes it very hard to browse and find information.
To get around missing headers I frequently find myself using a find command (CMD+F) to locate specific words or phrases. This can help, however, sometimes I have to guess at the keyword or topic I”m looking for - and it’s not always there.
This is where headers are useful. They give the writer a way to clearly signal where specific content lives on a page, or, if they use multiple sizes of headers, how various pieces of content could relate to others. They’re a bit similar to Confluence’s page tree - they let creators structure pieces of your content, both for themselves as a creator, but also for folks consuming that content.
As the example below shows, without headers pages quickly turn into word soup.
Anchors (links)

Another important feature of headers - and one that more people need to know about - is their ability to act as “Anchors”. Anchors are just another way of saying “hyperlinkable text”, and while you can add an anchor anywhere on a page you like (and link to it), headers are, by default, anchors themselves.
This means every header on your page has its own unique hyperlink. While it’s not immediately obvious, this means that you can link anyone directly to a specific header on a page. This greatly reduces the need for someone to scroll or CMD+F for content since you can send them directly to what they need instead of the top of the page.
Personally I find myself using this feature quite a bit - especially if I’m using Confluence to host a FAQ (I tend to make each question its own size 5 header, this makes it look like regular text, but function as an anchor). It’s also a great trick for bigger pages, or for ones with lots of headers.
Macros (Specifically Table of Contents)

The third major reason I like headers is because they interact with various macros - specifically “Table of Contents”. This macros automagically created a hyperlinked, nested, table of contents wherever you want. The macro uses the header size to build a nested list of headers, and does it in real-time as you’re editing so you can easily see what it looks like.
It also has some options that allow you to specify which levels of header should be used - for example you could exclude header level 1 if you wanted, which would allow you to use that for things like “background” or “table of contents”, while leaving the table of contents a bit more organized.
While you can get the same effect by manually typing out a table of contents and linking things, this is incredibly time-consuming and requires you to go and change it as the page is updated. I’ve been including this in all of my templates (and most of my pages!) as it helps with navigation (even with shorter pages). Setting the expectation that it will be at the top also helps my team more easily use content as they’ll know there’s always links to follow.
The Wrap Up
Headers are a great, simple, way to greatly improve the look, usefulness and ability of your pages. At the very least they’ll help you break up your content so it’s easier for readers to digest it, but they also offer some great additional features. Even better, they’re incredibly simple and easy to add!
Same text - without headers
Creating good content for a knowledge base or similar system is challenging. You have to determine what your audience needs, find experts who know those topics and ensure content is regularly maintained. There is, however, a very simple thing that can be done to improve almost every page in Confluence (and in many other similar systems) - use headers.
Headers are essentially just bigger text on a page, but despite their seemingly simple design they serve a number of important functions in Confluence.
Before you keep reading, scroll to the bottom of this post, I’ve copied all the content, but left out the headers…. It’s a bit hard to read, no?
The first, and arguable most important feature, or a header is to visually break up space on a page. I’ve lost track of the number of times I find really good content, but find it hard to read because it’s all just one gigantic wall of text. Paragraphs can (and do!) help with this, however, when all the text is the same size it makes it very hard to browse and find information.
To get around missing headers I frequently find myself using a find command (CMD+F) to locate specific words or phrases. This can help, however, sometimes I have to guess at the keyword or topic I”m looking for - and it’s not always there.
This is where headers are useful. They give the writer a way to clearly signal where specific content lives on a page, or, if they use multiple sizes of headers, how various pieces of content could relate to others. They’re a bit similar to Confluence’s page tree - they let creators structure pieces of your content, both for themselves as a creator, but also for folks consuming that content.
As the example below shows, without headers pages quickly turn into word soup.
Another important feature of headers - and one that more people need to know about - is their ability to act as “Anchors”. Anchors are just another way of saying “hyperlinkable text”, and while you can add an anchor anywhere on a page you like (and link to it), headers are, by default, anchors themselves.
This means every header on your page has its own unique hyperlink. While it’s not immediately obvious, this means that you can link anyone directly to a specific header on a page. This greatly reduces the need for someone to scroll or CMD+F for content since you can send them directly to what they need instead of the top of the page.
Personally I find myself using this feature quite a bit - especially if I’m using Confluence to host a FAQ (I tend to make each question its own size 5 header, this makes it look like regular text, but function as an anchor). It’s also a great trick for bigger pages, or for ones with lots of headers.
The third major reason I like headers is because they interact with various macros - specifically “Table of Contents”. This macros automagically created a hyperlinked, nested, table of contents wherever you want. The macro uses the header size to build a nested list of headers, and does it in real-time as you’re editing so you can easily see what it looks like.
It also has some options that allow you to specify which levels of header should be used - for example you could exclude header level 1 if you wanted, which would allow you to use that for things like “background” or “table of contents”, while leaving the table of contents a bit more organized.
While you can get the same effect by manually typing out a table of contents and linking things, this is incredibly time-consuming and requires you to go and change it as the page is updated. I’ve been including this in all of my templates (and most of my pages!) as it helps with navigation (even with shorter pages). Setting the expectation that it will be at the top also helps my team more easily use content as they’ll know there’s always links to follow.
Headers are a great, simple, way to greatly improve the look, usefulness and ability of your pages. At the very least they’ll help you break up your content so it’s easier for readers to digest it, but they also offer some great additional features. Even better, they’re incredibly simple and easy to add!

The burden of being a system administrator
Being a sys admin is important - but also it’s a position of trust
I became a system admin early in my career during a large system install. It was great! I got all kinds of new permissions, could do (almost) anything and it felt great.
What I didn't realize is that being a sys admin is more than getting extra permissions or access to new areas. Sure that's part of it's but being made a sys admin for any system is massive responsibility, and one that needs to be taken seriously.
This is doubly true if the system you administer handles any kind of sensitive data.. things like personally identifiable info, compensation data and the like. This information needs.to be carefully guarded and managed as it cause cause massive headaches if it gets out.
Even if you aren't the sys admin for a sensitive system, however, you still take on a lot of responsibilities.
Appropriate access
You will likely need to manage access to your system. This could involve adding new users changing existing access or revoking it as needed. You shouldn't also be the person who can approve access, so you'll need to follow a process and work with your approvers.
You should be very proactive with this part of being an admin. After all, you're being trusted to ensure only folks who should have access have it. This means you should be doing things like :
Regular audits - review who has what type of access andnget.it reapproved on a regular basis (quarertly, half-year).
Taking prompt action - This is especially true when a request to revoke access comes in. Make sure the person requesting it is authorized (e.g. a system owner, HR rep, legal etc), and then don't wait. 'This, however, also applies to other requests. Quick action both helps ensure the system is managed properly and helps build your credibility.
Be proactive - Be on the lookout for things that seem out of place, updates that are needed,
Troubleshooting
Since you have a ton of additional system access (frequently including the ability to see access log, or even log in as someone else) you will find yourself frequently having to troubleshoot issues. You also likely have a much deeper set of exoerienxes with ehateber system you're the admin for - both as a result of being and admin, but also because you interact with a wide range of system users.
This puts you in a strong position to help others learn to use the system or overcome challenges they find in it. These could be small questions, to massive disruptions. Regardless of the size, however, it is your job is to help solve it.
This could mean building documentation that folks can refer to, running training sessions, recording demonstrations and more. While each of these on their own may be a small thing, they add up over time, and help others more effective use the system.
Best practices
Typically being a sys admin goes beyond just pushing buttons to do things and moves into providing guidance and ideas on best practice. What is the best way to use the tool? What should it not be used for? What should we do now so we can do X in the future?
This area goes beyond technical knowledge of the system and gets into how the tool can be used. As an admin you likely are exposed to more ways a system can be utilized - this gives you a good perspective on how your team should use it.
Advising on best practices shows up in two main places - during planning and on an ongoing basis. Both involve you offering your expertise and knowledge, and both will require you to partner with whomever is looking to modify or use the system.
Wrap up
Being a sys admin can be a very fulfilling job. You'll learn a ton about the tech, and about the busiess. And even better, you'll help others do better at their jobs by removing friction and helping knock down blockers.

Atlassian Rovo
Rovo is a tool to help make sense of our data
A lot of the announcements at Team24 revolved around AI and how it will be integrated with all of Atlassian’s various tools. One big announcement, however, was about a specific AI feature called Rovo.
Rovo helps teams out by performing in three areas - search, learn and act.
Rovo Search
Companies have data, lots of data… how much data, you ask? Well, on average it’s something something like 2 billion data points spread across 200 systems. There is absolutely no way any sane person could make sense of that. Personally I have enough challenges keeping track of the information in the few systems I happen to use regularly that I don’t even consider how it can be combined or used with data from other places.
So we are forced to use tools. Unfortunately many of those tools only see a small portion of that data, making them useful only in specific instances. If I’m very lucky I’ll have an analyst or someone else who is familiar with other data sets that can help me make sense of everything - but that’s uncommon. Even when I do have an analyst who can help me out, we’re still frequently unable to pull everything together - either due to technical limitations (a specific data set isn’t available to us) or due to access or other considerations.
Rovo however, overcomes these challenges. It natively plugs into every Atlassian product, and knows how to interpret that information. This alone is a massive advantage over a human… many times I have to teach someone what data is available, what it means, etc… whereas Rovo knows all of that out of the box.
Even better, Rovo can be connected to non-Atlassian systems to gather information. Sure, this takes a bit of setup, but once it’s done, Rovo is able to analyst and add that data to what it already knows. While a human can certainly do this it takes time to learn the data sets (just like someone unfamiliar with how a Jira ticket is structured has to learn it), which slows down the process and opens it up to risk.
There is one big question that needs to be answered… Security. In order for Rovo to be tied into various systems, it inherently must have access to them. This means if I use Rovo to help me, it’s possible I’ll be exposed to data I don’t have access to… or does it?
It does not! Rovo is designed to respect the permission schemes of the source systems - so if I can’t access it with my credentials, Rovo won’t show it to me (even if Rovo can see it).
Rovo Learn
Data is great - it helps us make decisions, discover new things and make progress. Raw information, however, is generally useless without some type of analysis or organization. For example if you see a project name in a Confluence page it doesn’t really help you if I show you every page that mentions it. Humans are pretty good at finding patterns, discerning meaning and understanding what's going on, however, with the massive amounts of data flying around this is limited.
We are, after all, limited in the amount of information we can keep in our head. (I can barely remember where I leave my keys some days…) Systems like Rovo don’t have this limitation. (Sure there are technical limitations on it, but for the purposes of this discussion they’re effectively meaningless compared to the limitations a single human runs into). Rovo uses this capacity to help humans make sense of all that data.
For example, Rovo can assemble knowledge into “knowledge cards” that display information about a project including team members, milestones, metrics and more. This instantly allows a human to understand more about a project or team - and doesn’t require that human to pull apart multiple Confluence pages or other sources to learn that. Rovo does this by having access to all that underlying data, and is able to pull together contextual information from multiple places.
Rovo can also define terms and acronyms. Personally I’m a huge fan of guess what TLA (Three Letter Acronyms) mean, but not know, or not being able to easily figure them out, can be incredibly frustrating to folks joining a team. Rovo is able to do this across Atlassian, and non-Atlassian, systems. So not only will it define terms you see on a Jira ticket, but also in a Google Doc, or Outlook Email. Imagine how much less frustration folks would have with this type of information easily accessible.
And last but not least, Rovo supports natural language chat. This can either be done from the get-go, or as followup questions about anything it serves up. For me this is a massive plus as it allows users to gain trust in the system by asking clarifying questions. Rovo will even show where it found its information, giving users more confidence that the system is giving them positive information and not hallucinating or giving incorrect info.
Rovo act
Being able to parse through data and determine context, meaning and other things is a great ability of Rovo… however, it does take it one step further and helps users take various actions based on the data it see. Rovo has the concept of “agents” - essentially virtual team members - who can be designed to perform specific tasks.
Agents can be shaped to assist humans in a variety of ways.Imagine waking up and seeing a list of suggestions for how to prioritize your backlog, based on information Rovo knows about the project, its status, and team members. Or what if you needed to draft a marketing document, just ask a Rovo Agent - which has been developed and trained by your own marketing team on your company’s assets and tone - to help.
These Agents appear in the same places human team members appear, making them feel like a team member. To me this blurs the line between “tool” and “team member”, but not necessarily in a bad way. After all, learning how to use a tool can take time and can be frustrating, but if I treat that tool like a virtual team member, it cuts out a lot of the learning curve and friction.
Rovo Agents can be built from raw code, allowing developers a great deal of flexibility in defining what they do, how they behave and what access they have. They can, however, also be developed via no-code options. This allows less technically-inclined teams to develop and share agents with other teams - further enhancing their impact and reducing friction.
My take
We're only getting more systems and more data, so having a tool that is plugged into as much of it as possible and can help us make sense of it all is an obvious next step. This is double true when considering the amount of manual effort it would take to approximate this capability.
I can, however, see challenges in gaining adoption. For example groups may question how secure it is, or wonder how they know they can trust the tools output. After all, many LLM’s and AI operate in a bit of a black box, which can make it hard for humans to trust them (especially if they are used to being able to ask an analyst or other expert how they got to their conclusion.
These concerns, however, aren’t a reason to not develop or use this tech… it is, though, a reminder to be careful in how these tools are introduced to organizations and how they are managed. For example, instead of a “big bang” rollout begin small and find a group that's excited about it and develop targeted use cases. Work with them to determine other use cases, potential issues and other areas to expand into. Then let that group tell others about how useful it can be.
Overall I'm excited for tools like Rovo to come out, they’ll help free us up to do other more interesting things than fight with data. They’ll not only reduce the monotony that exists when wrangling large amounts of data, but also open new areas of inquiry and illuminate areas that otherwise would have been hidden. I can also easily see this tech help smaller teams have an outside impact by allowing them to extend into other areas.

Team 24 Confluence Updates
Lots of updates at Team24 for Confluence - see them here!
I’ve been over at Atlassian’s Team24 event (their yearly conference) and there are loads of interesting changes coming to their various products. There’s so many I’m going to focus posts on each system - starting with Confluence!
Whiteboards
AI sorting
Using whiteboards for ideation is a very common use case… I find, however, that the board easily gets full with sticky notes and other information. Sure, I can manually go through and sort them… but soon AI will sort them by category for us.
I can easily see how this will help teams gather their ideas, but more importantly organize and action them. It will also help reduce the time it takes for a team to go from “we’ve got an idea” to “what do we do”. Shortening this gap is important as the bigger it is, the more energy and excitement the team loses.
Voting
Folks will be able to vote directly on the whiteboard for their ideas. This looks similar to voting on a Jira issue - just click the thumbs up icon to vote on the sticky. Personally I haven’t used the voting features too much in Jira, but I’ve spoken to folks who find it very helpful in getting feedback from bigger groups.
This seems to be another great way to reduce the distance between “we’ve got an idea” and “what should be do”. Having it right in the whiteboard is also great, since folks won’t have to remember to look it up later and target what they wanted to do.
Databases
Pages can be built into databases
Personally I haven’t used databases very much as they’re a bit new, and missing some features I need… however, they now support the ability to build pages directly from a Database. This makes it easy to keep building out confluence and provides two-way linking between that page and the database.
This will speed up my process as I won’t have to go create a page, copy the link and come back any more… I can just create it from the database, use a template if I like and keep going. This will help keep me focused on my planning, and then circle back to the content.
Smart links can be added
This one is very interesting to me… we’re no longer limited to using only Confluence or Jira links within a database, we can link anything. And even better, that link can pull back information like a screenshot if it’s supported. This makes it much easier to build dynamic, and interesting, databases without having to manually copy in that additional content.
Smart links in Content Tree
In addition to smart links appearing in databases, they’ll also now be available in the content tree. Personally I find this to be exciting since many times the teams I work with have resources outside of confluence (e.g. tableau, google docs, whatever), so having the ability to pull them then directly into Confluence and make them a link only further helps reduce friction in using Confluence.
Search / AI
Page Catchup
This feature tracks changes made to a page since you last saw it and summarizes them for you. Essentially an extension of summarizing a page, but something I’ll personally find very helpful since things change a lot!.
Suggested Searches
Suggested searches will now appear (powered by AI) and results should be more accurate. This seems like a small update, but having Confluence suggest searches (similar to how Google autocompletes its search) is a big usability / quality of life feature. It will help folks find content they maybe didn’t know was there and expand their knowledge - the entire point of Confluence.
Search expansion
Search’s scope will expand beyond confluence and cover all atlassian products. This will allow folks to find related information in compass, jira and other places where it otherwise may be hiding.
I think this will make the search feature a lot more interesting / usable as information can easily be in various places. Allowing Search to find it beyond just the scope of the system you happen to be in will make it easier for folks to find what they’re looking for and increase the system’s overall usefulness.

The Importance of Tracking Changes
Every project goes through change… but it must be tracked!
Even the best planned project will need to change its plan at some point. Depending on the methodology used these can be easier, or more challenging, to incorporate, but regardless of how your project is run you’ll need some way of accepting, tracking, approving and deploying changes to The Plan.
Accepting change requests
The process begins with accepting requests for change. This can be as simple as someone adding a ticket to a backlog, and as complex as an official form someone has to fill out and submit to a specific person(s). Determining how your project will accept change should be considered during your planning process, and should be clearly documented.
This process should be shared with your project team and senior stakeholders as they’re the most likely groups to need to submit a change, but the process should also be setup to allow change requests from other sources (e.g. customers, suppliers, etc). Not only will they need access to the process itself, but ensure any documentation around how the overall process works is also available.
Tracking Changes
Change requests, regardless of viability or type, need to be tracked. This could be a simple whiteboard accessible to folks, or a complex software system. What you track may depend on your environment and specific needs of your team. At minimum, however, you should track the following information:
Tracking number - This is a unique identifier that allows folks to refer to a specific change request. This makes it easier to discuss and track throughout the system.
Description - A description of the requested change, including why it is being requested.
Requestor - The individual who requested the change. Followup questions, status updates and other things will be sent their way.
Status - Indicates where the request is in the workflow (e.g. “new”, “rejected”, “Accepted” etc).
Impacted area - The area of the project this request impacts. This could be a specific task(s), milestone or part of the project and is intended to help determine the risk this change request represents.
Approving Changes
Historically this is where I find waterfall projects get a bit of a bad rap since each change has to be evaluated by a change control board and approved or declined. This is an extreme version of change control, but it does offer some advantages that help ensure the change is handled as safely as possible:
Every change is evaluated
The appropriate stakeholders sign off on the change
Unfortunately it does have some downsides - mainly it can take a while for anything to get approved. This puts the project at risk of missing out on critical changes or pushing the timeline if something truly needed is delayed.
At the other end of the spectrum are approaches like Scrum, which allow anyone to submit a feature request or a change, which is then evaluated by the product owner. This has the opposite benefits of waterfall:
Much less friction in submitting requests
Changes can be evaluated and approved more quickly
Personally I find this makes it easier for changes to be considered, and adopted. That said, I also find that agile projects end up with a backlog that goes on forever as many groups don’t take time to go through and either reject, or archive, requests they won’t do.
Your specific will help dictate what your approval process is - typically some form of signoff is needed, however, how much evaluation each change goes through and who has to signoff can vary.
Monitor the Change
Approving changes helps avoid potential risk or negative side-effects, however, they still need to be monitored to ensure they place nice with the rest of the project. You can tailor your monitoring efforts to the size of the change - bigger changes = more monitoring - but in general I like to check in on any change a bit more frequently than other items.
Change is good… when controlled
Change isn’t anything to be afraid of - all projects go through it - but it is something to keep an eye on. Having a process, and making sure your team understands how to follow it, is critical to having changes happen in a graceful way.

Don't blame the tool
I frequently hear discussions along the lines of 'xuz is a terrible tool'. My knee jerk is to want to ask more - why do you think it's a terrible tool? What did it do or not do, to cause that reaction.
These are good question - but there are better ones to ask if you want to understand why someone thinks that. Questions like 'ehen it was setup did your team fully understand how to use XY tool? ', 'did the group who installed it take time to understand your needs?', 'did the folks using it get training on how to use it, and how to use it for your needs?'
Frequently I don't get answers to those questions because folks don't know. They inherited a system or joined the company after it was implemented. This is fine, however, I've noticed it can doom a system, and a team, to repeat mistakes and get stuck in blaming their tools.
Tools can be the source of trouble. They may lack a specific feature, or have bugs, or be hard to use. These are all legitimate complaints and issues that need to be addressed, or, at the very least, understood by the groups using it. After all, if I'm aware my tool has a known deficiency I can at least plan around it.
Many times, however, I find folks blame their tools without examining other things that contribute to their perception. Things like training, process mapping and understanding intended use.
Training
The eample I always think of here is an equity team I worked with wanting to stop using Jira and go back to zendesk. I asked them to brainstorm all their issues, and then share them with me. After that we met for half an hour, and I resolved all but one of their complaints, and solved the final one the next day.
Their complaints ranged from Jira not showing tickets a specific way to it missing features. The root cause wasn't that Jira was deficient, instead it was that the equity team didn't understand how to use the tool. They didnt know they could build a dashboard to show them information, or that they could easily reassing tickets.
Ensuring users, especially the ones responsible for using the system on a daily basis, know how to use the system is paramount to adoption - after all it's their job you're changing.
Process mapping
I'm frequently telling teams I work with that we shouldn't even consider using a system until we can map our our processes on a whiteboard. Being able to do this means we actually understand what the process is - who is responsible for what, where to go for help, etc. if we don't understand what it should be, there's no way a system can support it.
Process mapping is simple - just start drawing. Keep adding steps until either you don't know what's next or everyone agrees it's complete. Clearly indicate any gaps, and then go find someone to help fill them in (this can be a bit of a journey depending on how big the gap is!).
Don't start using a new system until you understand the process genetically - if you don't know it the system can't.
Intended use
Similar to understanding a process, understanding what a tool can, or should, be used for is a common challenge.

Schedule Crashing
Crashing means putting more resources on a task to finish it… but not all tasks are crashable!
Planning a project is a lot of work. There's dependencies, resources risks, assumptions, competing stakeholders and more. You've got to juggle all of those thoughts and demands and somehow come up with a project plan that gets you from nothing to something.
And then you realize some task won't get completed on time... There's just too much work. Luckily there's a way to help speed that up - crashing. Crashing a task is basically throwing more people at it to get it done faster. Only have one person and have ten widgets to build? Get five people and go five times as fast.
It is a great option for o help speed things up, but has several limitations that need to be understood....
You need to right resources
Every task in a project has a specific set of skills needed to complete. For example building a website requires someone who knows HTML and CSS. This need should be accounted for in planning to ensure the task can be accomplished, however, it doesn't mean you'll have others with the skill available to crash a task.
Depending on your team you could get lucky and have multiple individuals who have the necessary skills available to crash something. You might even be able to get by having one resource quickly train others (although this introduces a risk that they'll do something incorrectly...).many times, however you simply may not have the correct resource available.
Crashability
Many tasks can benefit from crashing. Data entry is one example I frequently run into... Two people will update a spreadsheet twice as quickly as one. Some physical tasks, like moving materials or preparing a work site are also good examples as multiple people can work together to speed them up.
There are, however, tasks where that isn't true... The standard example is having a baby - there simply isn't a way to speed that process up. Some tasks require waiting - for example proofing bread - that cannot be sped up even with more resources.
The challenge is to understand the difference - which takes can you crash, and which can you not? There are some characteristics I look for when trying to figure out if a task is crashable:
Repeatability - Are aspects of the task repetitive? If they are then the task may be a good candidate for crashing. Since the action actions happen multiple times they’re easier to train up others on, and there are more opportunities for others to help. Data entry is a good example of this.
Complexity - Simpler tasks tend to be more crashable as the skills needed are more widely available. This makes it more likely that your team has the skills spread across multiple resources.
Resource Availability - Getting more resources to work on a single task is more expensive - either in time, money or opportunity. There may be times when you simply cannot afford to crash since your resources are tied up elsewhere.
Crashing can be a great way to get things done in time - but like any tool you need to know how it’s best used, and the tradeoffs!

Handling Sensitive Information
Modern knowledge bases like Confluence are great things. They let us store and track information, share it with our teams, and make it incredibly easy to share information. While Confluence makes this process easy, sometimes it can make it TOO easy, allowing someone to accidentally share sensitive information.
We’ll dig into this problem, as well as how tools like SecurEnvoy (learn more here, and get a free trial) can help organizations mitigate the risk of sensitive information getting out.
The Problem
We’re in the information age - and information is everywhere. Fortunately tools like Confluence help us focus that into usable formats. While this is a great thing, it can end up hurting us if sensitive information gets shared to folks who shouldn’t have it. This information can run the gamut from things like business plans and project documents, to personally-sensitive things like Personally Identifiable Information (PII), health records, immigration information and more.
Tools like Confluence can also surface information to individuals outside your organization in the form of help center articles, product updates and more. This presents the possibility of sensitive information being exposed publicly, which is substantially worse than if it was only exposed to an internal audience.
Many modern systems do not have built-in systems or tools to help either prevent this information from being added to a system, or identify it if it’s in there. This creates a massive headache for groups that use these systems - how do you ensure your system does NOT contain sensitive information?
Solutions
There are several ways this problem can be addressed
Manual reviews
Get a group of people, teach them what to look for, and let them loose. After a time (typically determined by the size of your database) they’ll come back with their results.
Advantages
Anyone can do this - Just get some folks and train them on what to look for, and what to do when they find it
Disadvantages
Cost - This requires a large amount of person-hours to perform. You’ll either be pulling resources from other, more important, tasks, or hiring outside help to do it.
Risk - Even the best-trained individual can miss things, so you are exposing yourself to the risk they’ll miss something. In the realm of compliance this can be an incredibly costly mistake.
Continual effort - Your knowledge base is constantly changing, and these types of audits are only helpful for a point-in-time. By the time the audit is done, you may have to run another one.
Policy
Set clear policies and expectations so your team knows what information can be stored where.
Advantages
Compliance - Typically this type of policy is needed to ensure various compliance requirements (e.g. GDPR, SOX, etc) are met. Since you’ll need to be doing this anyway, make sure folks know about it.
Deflection - Many times people make an honest mistake and include sensitive information somewhere they shouldn’t. Educating them on what is OK to post helps avoid those mistakes.
Disadvantages
It’s passive - A policy can help prevent sensitive information from being posted, but it can’t actively stop it, or find violations.
Ignorance - Individuals may be unaware of the policy and violate it accidentally
Active Scanning
Use a tool, like SecurEnvoy, to actively scan your knowledge base, file servers, etc for potentially sensitive information.
Advantages
24/7 scanning - SecurEnvoy provides real-time scanning that identifies and helps mitigate sensitive information in a range of places (Confluence knowledge bases, end points, file servers, etc). And it doesn’t sleep….
Active mitigation - SecurEnvoy can take actions to help mitigate the risk, including tagging resources for followup action, emailing individuals and more
Cost savings - Automated tools have a significant cost saving over manual audits (check out this case-study of how a bank reduced scanning costs by over 93% by using SecurEnvoy).
Accuracy - Scanning software won’t misread numbers or make similar mistakes. Once you’ve setup your rules (e.g. find Credit Card numbers) it will find them. Every time.
Flexibility - SecurEnvoy lets you setup your own rules, for example searching for a project name, or unique character string. This allows you to define what is considered sensitive instead of being stuck with a set list.
Disadvantages
Setup cost - Active scanning tools have some type of setup cost (in time and dollars), however, they pay that back by
Administration - Someone needs to administer the tool (e.g. set it up, followup on alerts). Some, like SecurEnvoy, however, are mainly “set-and-forget” - once you’ve setup the scanning jobs just sit back and wait for alerts.
Path Forward
Focusing on a combination of Policies and Active Scanning is the best way to help ensure your systems don’t accidentally let sensitive information get exposed. Policies help reduce the chance sensitive information gets introduced to your systems, while tools like SecurEnvoy help catch it if some sensitive info gets out.
Curious to learn more? Check out SecurEnvoy here (and get a free trial)

Templates Are Your Friend
Templates help speed up your process, and make content more user friendly
I’ve created a lot of Confluence content. Sometimes the content I’m creating is unique, or at least uncommon. More often than not, though, the content I’m creating is similar to something else I”ve already done. How-to pages. Policies. Meeting notes. The list goes on.
Earlier in my career I found myself creating all that content from a blank page - it is, after all, the first thing you see when you click create. While this gave me a blank canvas to work on, I quickly found it to be time consuming to add the same formatting options, or macros, or headers time after after. It can also be a bit daunting to stare at that relatively blank space and get started.
A fix
So, I stole a trick I used in other systems - copy and paste! Just open up another page that looked like the one I wanted to build, copy everything and paste it on my new, blank page. This worked… However, it required that I go over the copy and remove anything that related to the page I was copying from. At best this resulted in me taking more time than I would prefer, at worst I’d miss something and leave incorrect information on a page (not the end of the world, but annoying and embarrassing!).
This process of copy, paste, edit, write continued for a while, until someone pointed out Templates existed. I’m honestly not sure how or why I didn’t use them before, but once I did I got a lot faster at creating solid content.
Managing Templates
The sheer number of available templates is a bit staggering, so I quickly found it worth my time to manage them a bit:
Use the search bar and filter options - You can certainly scroll through the 100+ templates in confluence… but that takes time. Instead, just use the search bar at the top (or the filter options) to quickly pare down the list.
Star favorites - Starring favorites makes it much easier to locate and it only takes a few seconds to do. Typically I find myself only using a handful of templates (even including new ones I’ve made), so doing this is more than worthwhile.
Remove them - If you’re really feeling up for it, go into space settings and remove unnecessary templates. Personally I find I don’t do this since it takes a bit of time, but many of the templates displayed never get used, so just rip them out.
Edit existing ones - Sometimes you’ll find a template that doesn’t QUITE meet your needs… don’t suffer through editing it every time you want to use it - instead go edit the template in space settings. This ensures every time you use it, it will be exactly what you need.
Make new ones - While the 100+ stock templates can be useful, you will likely find you have a specific need they don’t meet. Take some time to make your own template the fits your exact use case. This does take a bit of time, but it will both save you time constantly editing new pages, and also remove the mental burden or worrying about that time spent.
Other benefits
I’ve found that taking time to manage templates in a space doesn’t just help me, it helps everyone else creating content. Many folks I talk to mention formatting and not knowing how to setup a page as being a hurdle to making content, so by cleaning up templates and making them more useful to your team you’ll be helping knock down barriers to entry.